Technical Details
The main simplification we made is naming gradient boosting a neural network. Since society has a clear familiarity with neural networks, we decided not to bother explaining what boosting is, as no one really cares.
So we used everyone's favorite CatBoost from Yandex. Because it works quickly and is easy to train.
loss_function - MultiClass
eval_metric - TotalF1
test_size - 40%
The final Total F1 was 64 percent on the test set. Note that this is multi-class! We are predicting not a boolean variable, but classes, of which there were 80. We decided to remove 10 countries from the data, as there were fewer than 1000 respondents there. Turkey changed its questions significantly, so we simply removed it from the data.
We could have further increased the Total F1, but it was a waste of time. In principle, if you feed all the questions, you get 92% accuracy right away! Some questions might have been spoilers for the model, but I don't see a point in further improvement. We also didn't want to make the survey too long. In any case, a person falls into their cluster based on life values.
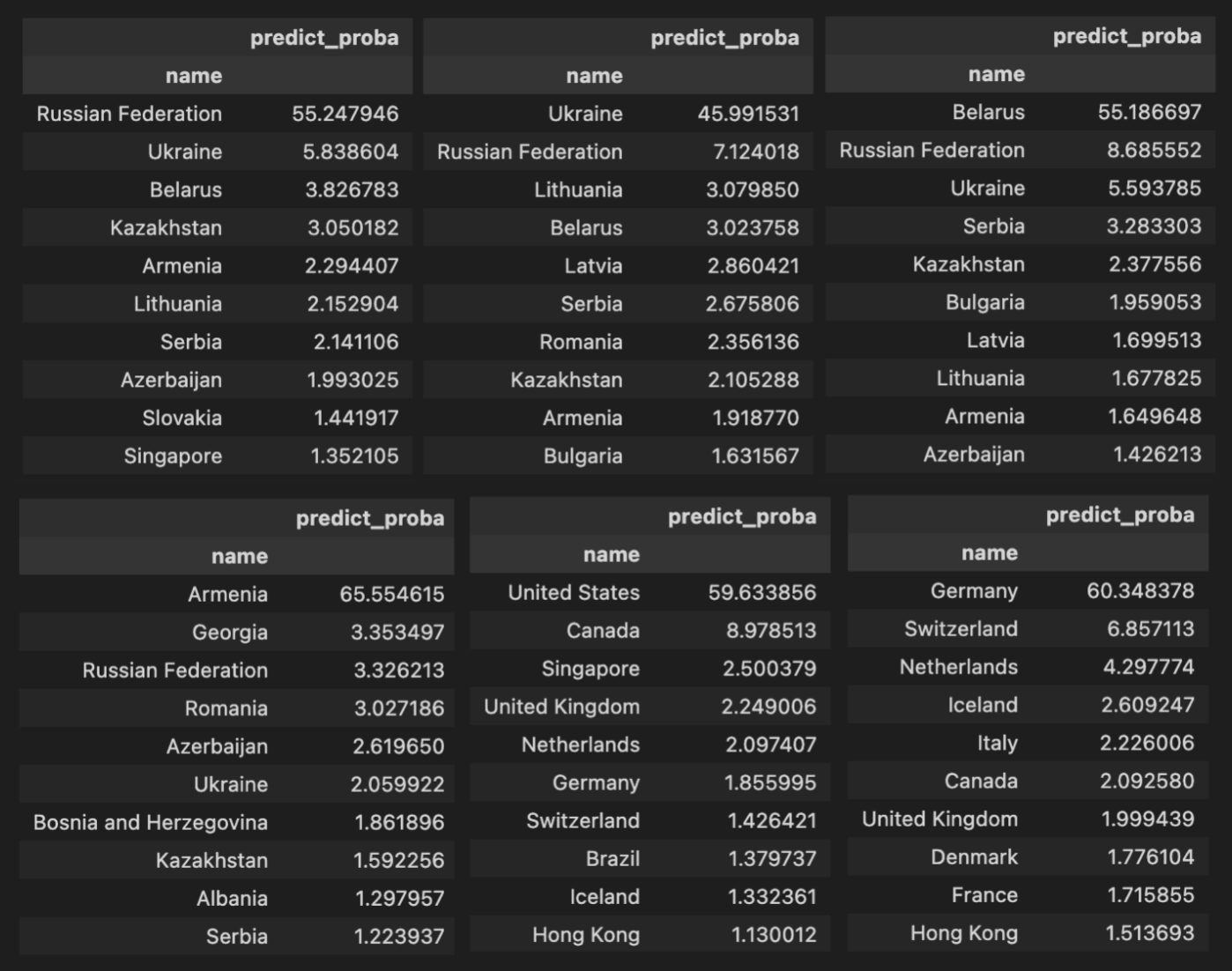
Here are examples of some countries. Each table is a filter of the table by country. And the overall model score for all countries in the test set. For example, the first table shows respondents from Russia from the test set and the model's answers based on their responses.
So we used everyone's favorite CatBoost from Yandex. Because it works quickly and is easy to train.
loss_function - MultiClass
eval_metric - TotalF1
test_size - 40%
The final Total F1 was 64 percent on the test set. Note that this is multi-class! We are predicting not a boolean variable, but classes, of which there were 80. We decided to remove 10 countries from the data, as there were fewer than 1000 respondents there. Turkey changed its questions significantly, so we simply removed it from the data.
We could have further increased the Total F1, but it was a waste of time. In principle, if you feed all the questions, you get 92% accuracy right away! Some questions might have been spoilers for the model, but I don't see a point in further improvement. We also didn't want to make the survey too long. In any case, a person falls into their cluster based on life values.
Confusion Matrix
Here's an interesting thing, you can see which countries the model confuses most often. But you can also rephrase the question and ask which countries are similar to each other since the model confuses their citizens.Here are examples of some countries. Each table is a filter of the table by country. And the overall model score for all countries in the test set. For example, the first table shows respondents from Russia from the test set and the model's answers based on their responses.