技術の詳細
私たちが行った主な単純化は、勾配ブースティングをニューラルネットワークと呼ぶことです。社会ではニューラルネットワークについての明確な理解があるため、ブースティングとは何かを説明する手間をかける必要はないと考えました。
したがって、私たちはみんなのお気に入りである Yandex の CatBoost を使用しました。なぜなら、それは速く動作し、トレーニングが簡単だからです。
loss_function - MultiClass
eval_metric - TotalF1
test_size - 40%
最終的な Total F1 スコアはテストセットで 64% でした。これはマルチクラスです。私たちは真偽変数ではなく、80 のクラスを予測しています。1000 人未満の回答者がいるため、データから 10 の国を削除することにしました。トルコは質問を大幅に変更したため、データから削除しました。
Total F1 をさらに向上させることは可能でしたが、それには時間がかかりすぎるでしょう。原則として、すべての質問を入力すれば、即座に 92% の精度が得られるでしょう!モデルに対する一部の質問はヒントかもしれませんが、さらなる改善の意味はありません。また、調査が長すぎることは望ましくありません。いずれにしても、人々は生活価値に基づいてクラスターにグループ化されます。
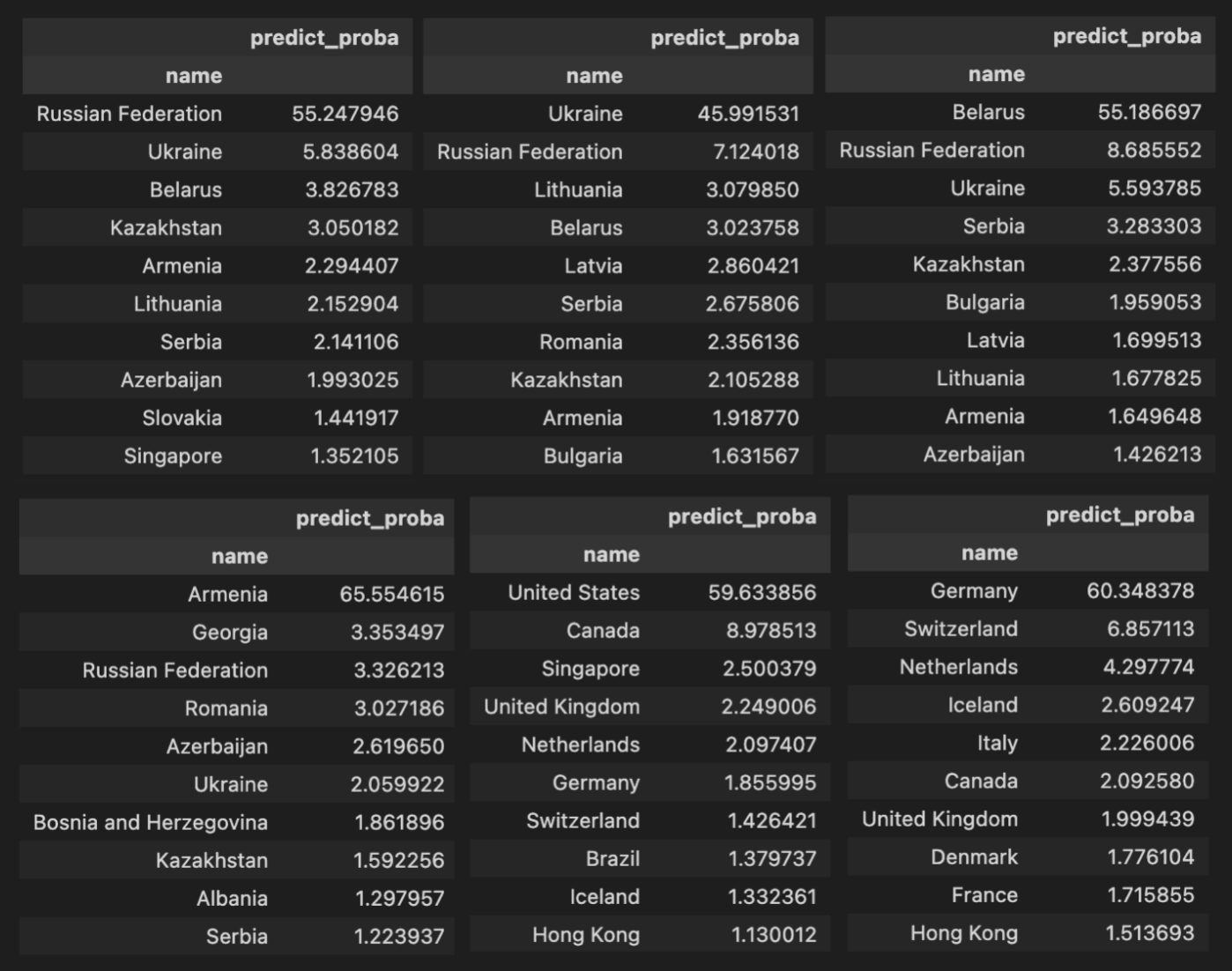
いくつかの国の例を示します。各テーブルは国によるデータのフィルタリングを表しています。およびテストセットのすべての国に対するモデルの総合評価。例えば、最初のテーブルはテストセット内のロシアからの回答者と、その回答に基づくモデルの回答を表しています。
したがって、私たちはみんなのお気に入りである Yandex の CatBoost を使用しました。なぜなら、それは速く動作し、トレーニングが簡単だからです。
loss_function - MultiClass
eval_metric - TotalF1
test_size - 40%
最終的な Total F1 スコアはテストセットで 64% でした。これはマルチクラスです。私たちは真偽変数ではなく、80 のクラスを予測しています。1000 人未満の回答者がいるため、データから 10 の国を削除することにしました。トルコは質問を大幅に変更したため、データから削除しました。
Total F1 をさらに向上させることは可能でしたが、それには時間がかかりすぎるでしょう。原則として、すべての質問を入力すれば、即座に 92% の精度が得られるでしょう!モデルに対する一部の質問はヒントかもしれませんが、さらなる改善の意味はありません。また、調査が長すぎることは望ましくありません。いずれにしても、人々は生活価値に基づいてクラスターにグループ化されます。
混同行列
ここで面白いことがあります。モデルが最もよく混同する国を見ることができます。しかし、同時に質問を再構築し、どの国が最も類似しているか尋ねることもできます。なぜなら、モデルがその市民を混同するからです。いくつかの国の例を示します。各テーブルは国によるデータのフィルタリングを表しています。およびテストセットのすべての国に対するモデルの総合評価。例えば、最初のテーブルはテストセット内のロシアからの回答者と、その回答に基づくモデルの回答を表しています。