Detalles Técnicos
La principal simplificación que hicimos es referirnos al impulso de gradiente como una red neuronal. Dado que hay una clara familiaridad con las redes neuronales en la sociedad, decidimos no molestarnos en explicar qué es el impulso, ya que a nadie le importa.
Así que usamos el CatBoost favorito de todos de Yandex. Porque funciona rápido y es fácil de entrenar.
loss_function - MultiClass
eval_metric - TotalF1
test_size - 40%
La puntuación final de Total F1 fue del 64 por ciento en el conjunto de pruebas. Por favor, tenga en cuenta que esto es multi-clase. No estamos prediciendo una variable booleana, sino clases, de las cuales había 80. Decidimos eliminar 10 países de los datos, ya que tenían menos de 1000 encuestados. Turquía cambió sus preguntas significativamente, así que simplemente la eliminamos de los datos.
Era posible mejorar aún más el Total F1, pero hubiera requerido mucho tiempo. En principio, si alimentáramos todas las preguntas, ¡alcanzaríamos una precisión del 92% de inmediato! Algunas preguntas podrían haber sido pistas para el modelo, pero no veo sentido en seguir mejorando. Además, no era deseable hacer la encuesta demasiado larga. En cualquier caso, las personas se agrupan en sus clústeres según sus valores de vida.
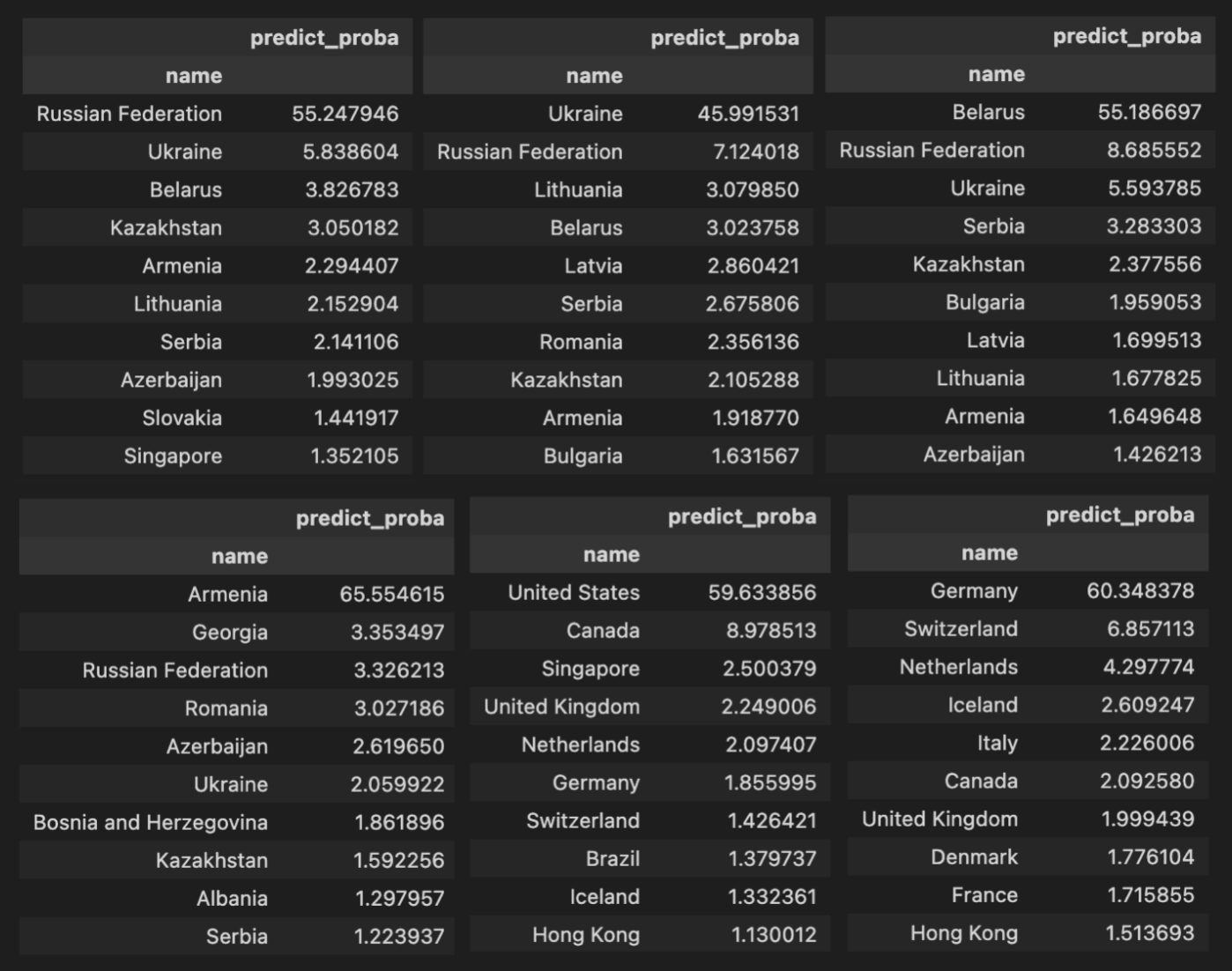
Aquí hay ejemplos de algunos países. Cada tabla representa la filtración de los datos por país. Y la evaluación general del modelo para todos los países en el conjunto de pruebas. Por ejemplo, la primera tabla representa a los encuestados de Rusia en el conjunto de pruebas y las respuestas del modelo basadas en sus respuestas.
Así que usamos el CatBoost favorito de todos de Yandex. Porque funciona rápido y es fácil de entrenar.
loss_function - MultiClass
eval_metric - TotalF1
test_size - 40%
La puntuación final de Total F1 fue del 64 por ciento en el conjunto de pruebas. Por favor, tenga en cuenta que esto es multi-clase. No estamos prediciendo una variable booleana, sino clases, de las cuales había 80. Decidimos eliminar 10 países de los datos, ya que tenían menos de 1000 encuestados. Turquía cambió sus preguntas significativamente, así que simplemente la eliminamos de los datos.
Era posible mejorar aún más el Total F1, pero hubiera requerido mucho tiempo. En principio, si alimentáramos todas las preguntas, ¡alcanzaríamos una precisión del 92% de inmediato! Algunas preguntas podrían haber sido pistas para el modelo, pero no veo sentido en seguir mejorando. Además, no era deseable hacer la encuesta demasiado larga. En cualquier caso, las personas se agrupan en sus clústeres según sus valores de vida.
Matriz de Confusión
Aquí hay algo interesante. Podemos ver qué países confunde más a menudo el modelo. Pero también podemos reformular la pregunta y preguntar qué países se parecen más entre sí, ya que el modelo confunde a sus ciudadanos.Aquí hay ejemplos de algunos países. Cada tabla representa la filtración de los datos por país. Y la evaluación general del modelo para todos los países en el conjunto de pruebas. Por ejemplo, la primera tabla representa a los encuestados de Rusia en el conjunto de pruebas y las respuestas del modelo basadas en sus respuestas.