Technische Details
Die wichtigste Vereinfachung, die wir vorgenommen haben, ist es, das Gradienten-Boosting als neuronales Netzwerk zu bezeichnen. Da es in der Gesellschaft eine klare Vertrautheit mit neuronalen Netzwerken gibt, haben wir uns entschlossen, uns nicht die Mühe zu machen, zu erklären, was Boosting ist, da es niemanden interessiert.
Daher haben wir den von allen bevorzugten CatBoost von Yandex verwendet. Weil er schnell funktioniert und leicht zu trainieren ist.
loss_function - MultiClass
eval_metric - TotalF1
test_size - 40%
Die endgültige Total F1-Bewertung betrug 64 Prozent im Testset. Bitte beachten Sie, dass dies eine Mehrklassen-Klassifikation ist! Wir sagen nicht eine boolesche Variable voraus, sondern Klassen, von denen es 80 gibt. Wir haben beschlossen, 10 Länder aus den Daten zu entfernen, da sie weniger als 1000 Befragte hatten. Die Türkei hat ihre Fragen stark verändert, daher haben wir sie einfach aus den Daten entfernt.
Es war möglich, die Total F1 noch weiter zu verbessern, aber das hätte zu viel Zeit in Anspruch genommen. Grundsätzlich hätten wir bei Fütterung aller Fragen sofort eine Genauigkeit von 92 % erreicht! Einige Fragen könnten für das Modell Hinweise sein, aber ich sehe keinen Sinn in weiterer Verbesserung. Außerdem war es nicht wünschenswert, die Umfrage zu lange zu machen. In jedem Fall werden Menschen nach ihren Lebenswerten gruppiert.
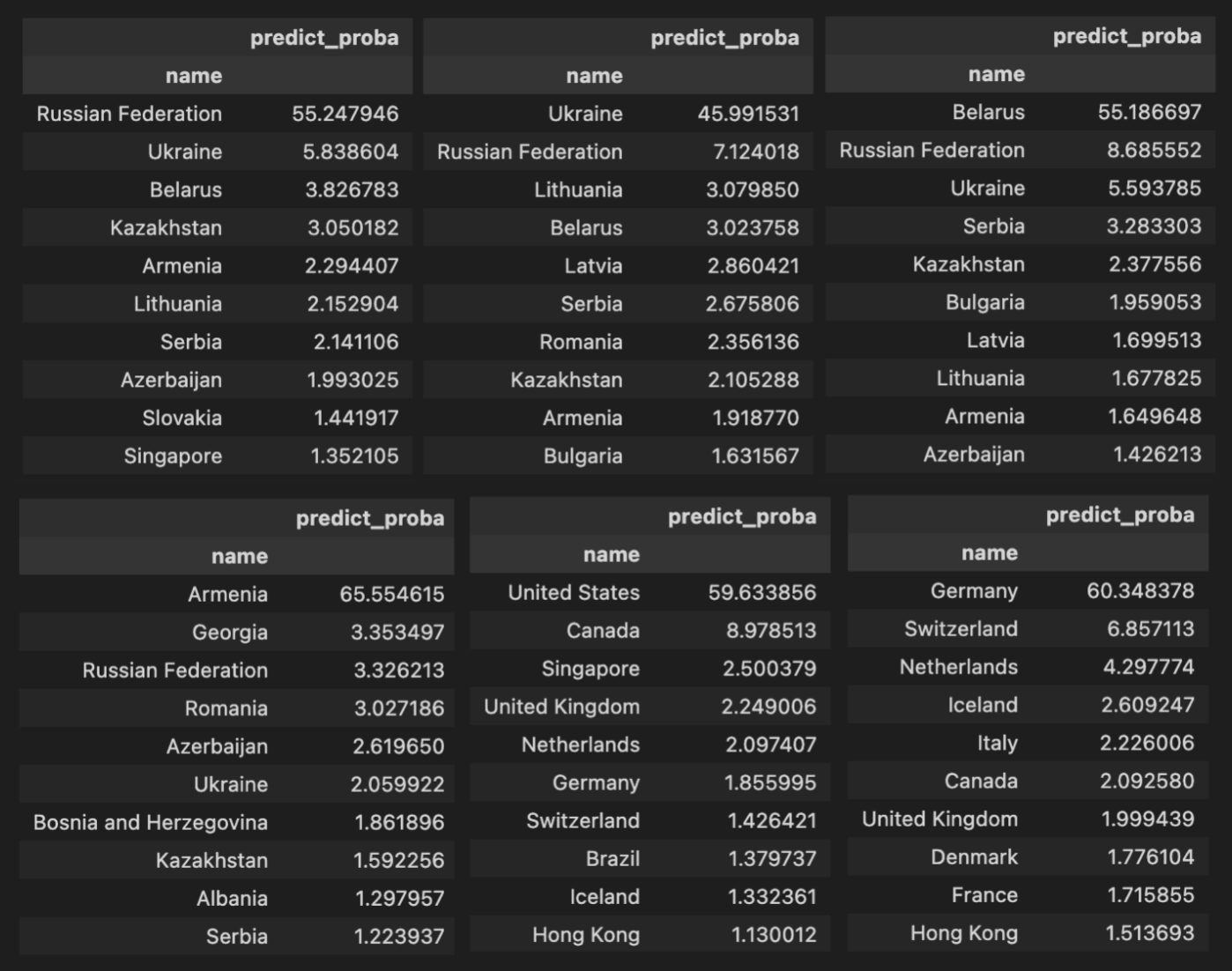
Hier sind Beispiele einiger Länder. Jede Tabelle repräsentiert die Datenfilterung nach Land. Und die Gesamtbewertung des Modells für alle Länder im Testset. Zum Beispiel repräsentiert die erste Tabelle die Befragten aus Russland im Testset und die Antworten des Modells auf der Grundlage ihrer Antworten.
Daher haben wir den von allen bevorzugten CatBoost von Yandex verwendet. Weil er schnell funktioniert und leicht zu trainieren ist.
loss_function - MultiClass
eval_metric - TotalF1
test_size - 40%
Die endgültige Total F1-Bewertung betrug 64 Prozent im Testset. Bitte beachten Sie, dass dies eine Mehrklassen-Klassifikation ist! Wir sagen nicht eine boolesche Variable voraus, sondern Klassen, von denen es 80 gibt. Wir haben beschlossen, 10 Länder aus den Daten zu entfernen, da sie weniger als 1000 Befragte hatten. Die Türkei hat ihre Fragen stark verändert, daher haben wir sie einfach aus den Daten entfernt.
Es war möglich, die Total F1 noch weiter zu verbessern, aber das hätte zu viel Zeit in Anspruch genommen. Grundsätzlich hätten wir bei Fütterung aller Fragen sofort eine Genauigkeit von 92 % erreicht! Einige Fragen könnten für das Modell Hinweise sein, aber ich sehe keinen Sinn in weiterer Verbesserung. Außerdem war es nicht wünschenswert, die Umfrage zu lange zu machen. In jedem Fall werden Menschen nach ihren Lebenswerten gruppiert.
Verwirrungsmatrix
Hier passiert etwas Interessantes. Wir können sehen, welche Länder das Modell am häufigsten verwechselt. Aber man kann die Frage auch umformulieren und fragen, welche Länder einander am ähnlichsten sind, da das Modell deren Bürger verwechselt.Hier sind Beispiele einiger Länder. Jede Tabelle repräsentiert die Datenfilterung nach Land. Und die Gesamtbewertung des Modells für alle Länder im Testset. Zum Beispiel repräsentiert die erste Tabelle die Befragten aus Russland im Testset und die Antworten des Modells auf der Grundlage ihrer Antworten.