تفاصيل تقنية
أهم التبسيطات التي قمنا بها هي تسمية التعزيز بالتدرج بشبكة عصبية. نظرًا لأن هناك توافرًا واضحًا للتعرف على الشبكات العصبية في المجتمع، قررنا عدم العناء في شرح مفهوم التعزيز بالتدرج حيث لا أحد يهتم.
لذلك، استخدمنا CatBoost من Yandex، المفضل للجميع. لأنه يعمل بسرعة وسهل التدريب.
loss_function - MultiClass
eval_metric - TotalF1
test_size - 40%
النتيجة النهائية لمقياس الـ F1 الإجمالي كانت 64٪ في مجموعة الاختبار. يرجى ملاحظة أن هذه تصنيف متعدد الفئات! لا نقوم بالتنبؤ بمتغير بولياني، بل بفئات، منها 80 فئة. قررنا إزالة 10 دول من البيانات لأنها كانت تحتوي على أقل من 1000 مشارك. تغيرت تركيا كثيرًا في أسئلتها، لذلك قمنا ببساطة بإزالتها من البيانات.
كان من الممكن تحسين نتيجة الـ F1 الإجمالي بشكل أكبر، ولكن ذلك كان سيستغرق وقتًا طويلاً. في المبدأ، إذا قمنا بتغذية جميع الأسئلة، سنحقق دقة تصل إلى 92% فورًا! قد تكون بعض الأسئلة إشارات للنموذج، ولكن لا أرى معنى في تحسينات إضافية. بالإضافة إلى ذلك، لم يكن من المرغوب فيه جعل الاستبيان طويلاً جدًا. على أي حال، يتم تجميع الأشخاص استنادًا إلى قيمهم في الحياة.
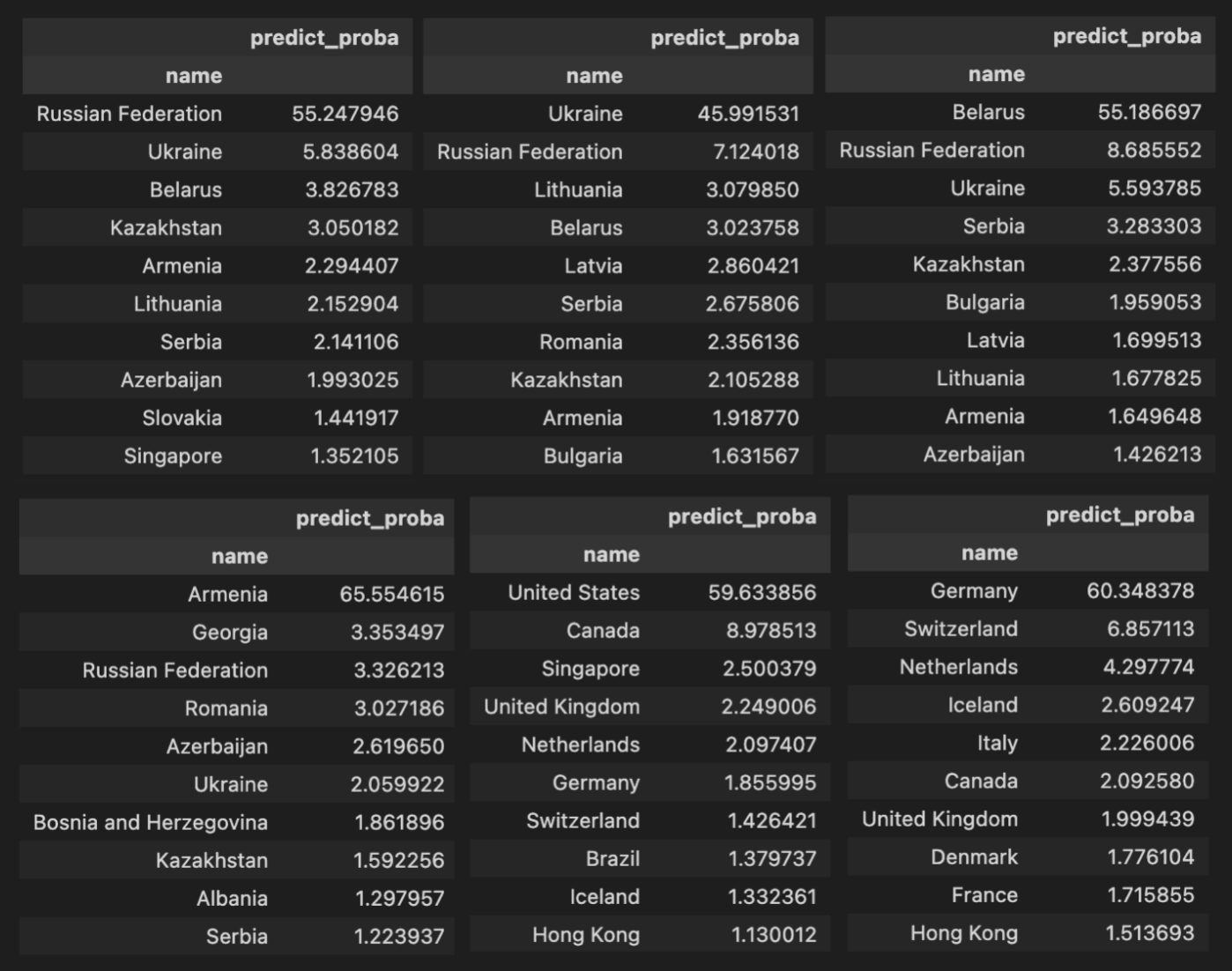
فيما يلي أمثلة على بعض البلدان. تمثل كل جدول تصفية البيانات حسب البلد. والتقييم العام للنموذج لجميع البلدان في مجموعة الاختبار. على سبيل المثال، يمثل الجدول الأول المشاركين من روسيا في مجموعة الاختبار والإجابات التي قدمها النموذج بناءً على إجاباتهم.
لذلك، استخدمنا CatBoost من Yandex، المفضل للجميع. لأنه يعمل بسرعة وسهل التدريب.
loss_function - MultiClass
eval_metric - TotalF1
test_size - 40%
النتيجة النهائية لمقياس الـ F1 الإجمالي كانت 64٪ في مجموعة الاختبار. يرجى ملاحظة أن هذه تصنيف متعدد الفئات! لا نقوم بالتنبؤ بمتغير بولياني، بل بفئات، منها 80 فئة. قررنا إزالة 10 دول من البيانات لأنها كانت تحتوي على أقل من 1000 مشارك. تغيرت تركيا كثيرًا في أسئلتها، لذلك قمنا ببساطة بإزالتها من البيانات.
كان من الممكن تحسين نتيجة الـ F1 الإجمالي بشكل أكبر، ولكن ذلك كان سيستغرق وقتًا طويلاً. في المبدأ، إذا قمنا بتغذية جميع الأسئلة، سنحقق دقة تصل إلى 92% فورًا! قد تكون بعض الأسئلة إشارات للنموذج، ولكن لا أرى معنى في تحسينات إضافية. بالإضافة إلى ذلك، لم يكن من المرغوب فيه جعل الاستبيان طويلاً جدًا. على أي حال، يتم تجميع الأشخاص استنادًا إلى قيمهم في الحياة.
مصفوفة الالتباس
هنا يحدث شيء مثير للاهتمام. يمكننا رؤية البلدان التي يخلطها النموذج بشكل أكثر تكرارًا. ولكن يمكن أيضًا إعادة صياغة السؤال والسؤال عن البلدان التي تشبه بعضها البعض بشكل أكبر، حيث يخلط النموذج بين مواطنيهم.فيما يلي أمثلة على بعض البلدان. تمثل كل جدول تصفية البيانات حسب البلد. والتقييم العام للنموذج لجميع البلدان في مجموعة الاختبار. على سبيل المثال، يمثل الجدول الأول المشاركين من روسيا في مجموعة الاختبار والإجابات التي قدمها النموذج بناءً على إجاباتهم.